**
This is an expanded and improved version of a talk I gave at the last AHA! meeting here in Austin. My slides for that talk can be found here
**
Recently I've been working on my windbg extension,
narly. Part of my intended purpose for it is to be able to search for ROP gadgets, but to do that I needed to find a disassembler that I could use. I couldn't use the disassembler available through the windbg extension API, since the only thing you can do is call
IDebugControl::Disassemble, which just returns a string of the disassembly. I could have used a number of other open-source disassemblers, but decided to reinvent the wheel and write my own. A lot of people would groan at the thought of reinventing the wheel, but I
usually enjoy it since it's one of the best ways I learn.
I've been coding my disassembler straight from the Intel® 64 and IA-32 Architectures
Software Developer's Manual:
Volume 2A: Instruction Set Reference, A-M and
Volume 2B: Instruction Set Reference, N-Z. Reading through specs that define how things are supposed to behave is always interesting, because you start to understand some of the boundaries/corner cases and see ways that some potentially interesting behaviors might occur. This blog post is about some interesting techniques I've come across to represent the same instruction in multiple ways (using a different set of bytes to do the exact same thing.)
Note that I've only been able to test this out on Intel processors.
To understand most of what I'll be talking about, you'll have to somewhat understand the parts of an x86 instruction, as well as the "rules" that go with them. Once I go over the "rules", I'll then explain the ways I've come up with to represent the same instruction using different sets of bytes, both by following the rules and by breaking them.
instructions and rules
An x86 instruction is made up of several parts:
+----------+--------+--------+-----+--------------+-----------+
| prefixes | opcode | modR/M | sib | displacement | immediate |
+----------+--------+--------+-----+--------------+-----------+
Everybody knows the opcode part of an instruction, but I'm betting fewer know how the other parts of an instruction work and interact.
prefixes
+----------+--------+--------+-----+--------------+-----------+
| prefixes | opcode | modR/M | sib | displacement | immediate |
+----------+--------+--------+-----+--------------+-----------+
Prefixes are bytes that precede the opcode and modify the meaning or action of the instruction. A single instruction can have up to four separate prefixes (one byte each). Prefixes can be arranged in any order. Below is the list of available prefixes:
prefix | name
-------+-----------------------
0xf0 | LOCK
0xf2 | REPNE/REPZ
0xf3 | REPE/REPZ
|
0x2e | CS Segment override
0x36 | SS Segment override
0x3e | DS Segment override
0x26 | ES Segment override
0x64 | FS Segment override
0x65 | GS Segment override
|
0x2e | *Branch not taken
0x3e | *Branch taken
|
0x66 | Operand-size override
0x67 | Address-size override
*for use only with Jcc instructions
The intel manual says "it is only useful to include up to one prefix code from each of the four groups". This means that an instruction like the one below shouldn't "be useful", since the lock and the rep prefixes are both from the same group:
lock rep add dword ptr[eax],eax
Windbg seems to think that it's not only "not useful", but invalid as well (f0 = lock, f3 = rep):
01011a3f f0 ???
01011a40 f30100 rep add dword ptr [eax],eax
Also, some of the prefixes are supposed to only be used with certain instructions. If they are used with other instructions, the behavior is undefined. For example, the branch prefixes (3e and 2e) are only supposed to be applied to the Jcc instructions (conditional jmps). Applying them to other instructions should yield unexpected behavior.
Below are some examples of the affects prefixes have on instructions:
prefixes | opcode | modRM | sib | disp | imm | disasm
--------------+--------+-------+-----+----------+----------+--------
| 59 | | | | | pop ecx
66 | 59 | | | | | pop cx
f366 | 59 | | | | | rep pop cx
f266 | 59 | | | | | repne pop cx
f22e66 | 59 | | | | | repne pop cx
| | | | | |
| 8b | 03 | | | | mov eax,dword ptr [ebx]
67 | 8b | 03 | | | | mov eax,dword ptr [bp+di]
6667 | 8b | 03 | | | | mov ax,word ptr [bp+di]
663e | 8b | 03 | | | | mov ax,word ptr ds:[ebx]
| | | | | |
| 01 | 00 | | | | add dword ptr[eax],eax
f0 | 01 | 00 | | | | lock add dword ptr[eax],eax
opcode
+----------+--------+--------+-----+--------------+-----------+
| prefixes | opcode | modR/M | sib | displacement | immediate |
+----------+--------+--------+-----+--------------+-----------+
An opcode is the core of an instruction. Everything else is supplementary to it. An opcode can be up to four bytes long, and might include a mandatory prefix.
Each opcode determines how its operands are encoded. For example, an opcode might use the modR/M byte, modR/M and sib bytes, or modR/M byte and displacement,
prefixes | opcode | modRM | sib | disp | imm | disasm
--------------+--------+-------+-----+----------+----------+--------
| 8b | 03 | | | | mov eax,dword ptr[ebx]
| 8b | 04 | bb | | | mov eax,dword ptr[ebx+edi*4]
| 8b | 83 | | 10203040 | | mov eax,dword ptr[ebx+40302010]
an immediate value,
prefixes | opcode | modRM | sib | disp | imm | disasm
--------------+--------+-------+-----+----------+----------+--------
| b8 | | | | aabbccdd | mov eax,ddccbbaa
or add a register index to the opcode:
prefixes | opcode | modRM | sib | disp | imm | disasm
--------------+--------+-------+-----+----------+----------+--------
| 58 | | | | | pop eax eax = 00
| 59 | | | | | pop ecx ecx = 01
| 5a | | | | | pop edx edx = 02
| 5b | | | | | pop ebx ebx = 03
| 5c | | | | | pop esp esp = 04
| 5d | | | | | pop ebp ebp = 05
| 5e | | | | | pop esi esi = 06
| 5f | | | | | pop edi edi = 07
modR/M
+----------+--------+--------+-----+--------------+-----------+
| prefixes | opcode | modR/M | sib | displacement | immediate |
+----------+--------+--------+-----+--------------+-----------+
The modR/M byte is made up of three parts:
0 1 2 3 4 5 6 7
+---+---+---+---+---+---+---+---+
| mod |reg/opcode | r/m |
+-------+-----------+-----------+
The modR/M byte uses either a 16-bit or 32-bit addressing mode. The 0x67 prefix (operand size override) switches the addressing mode from 32 to 16 bit.
Depending on the value of the r/m part of the modR/M byte, the sib byte (32-bit addressing mode only) or a displacement (16 or 32) may also be required. Also, if there is no second operand, the reg/opcode part may be used as an opcode extension.
There are two tables that define the meaning of the modR/M byte, one for each addressing mode:
Below are examples of different ways the modR/M byte might be used:
prefixes | opcode | modRM | sib | disp | imm | disasm
--------------+--------+-------+-----+----------+----------+--------
| 8b | 03 | | | | mov eax,dword ptr [ebx]
| 8b | 05 | |aabbccdd | | mov eax,dword ptr ds:[ddccbbaa]
| 8b | 41 | | 10 | | mov eax,dword ptr[ecx+10]
| | | | | |
67 | 8b | 03 | | | | mov eax, dword ptr[bp+di]
67 | 8b | 05 | | | | mov eax, dword ptr[di]
67 | 8b | 0c | | | | mov ecx, dword ptr[si]
67 | 8b | 41 | | 10 | | mov eax, dword ptr[bx+di+10]
67 | 8b | 81 | | 1010 | | mov eax, dword ptr[bx+di+1010]
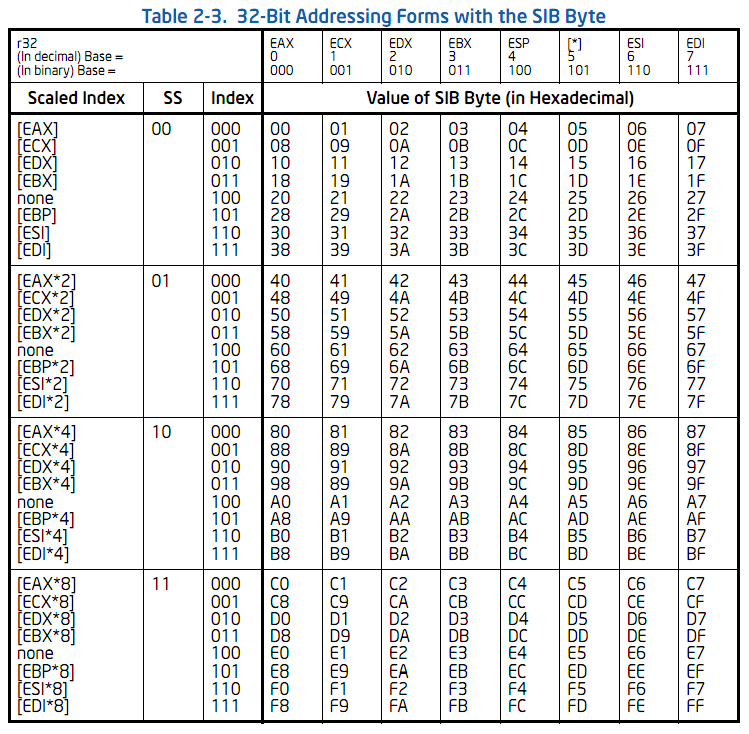
sib
+----------+--------+--------+-----+--------------+-----------+
| prefixes | opcode | modR/M | sib | displacement | immediate |
+----------+--------+--------+-----+--------------+-----------+
The sib byte is only required when the "Effective Address" column in the 32-bit modR/M table has a value that looks like
The sib byte has three parts:
0 1 2 3 4 5 6 7
+---+---+---+---+---+---+---+---+
| scale | index | base |
+-------+-----------+-----------+
This byte is used to make instructions behave like this:
prefixes | opcode | modRM | sib | disp | imm | disasm
--------------+--------+-------+-----+----------+----------+--------
| 8b | 1c | 83 | | | mov ebx,dword ptr[ebx+eax*4]
| | \----> scale
| |
| \----> index
|
\----> base
The sib byte's meaning is defined by the table below:
Some examples on using the sib byte are below:
prefixes | opcode | modRM | sib | disp | imm | disasm
--------------+--------+-------+-----+----------+----------+--------
| 8b | 1c | 03 | | | mov ebx,dword ptr[ebx+eax]
| 8b | 1c | 43 | | | mov ebx,dword ptr[ebx+eax*2]
| 8b | 1c | 83 | | | mov ebx,dword ptr[ebx+eax*4]
| 8b | 1c | c3 | | | mov ebx,dword ptr[ebx+eax*8]
| | | | | |
| 8b | 1c | 23 | | | mov ebx,dword ptr[ebx]
| 8b | 1c | 63 | | | mov ebx,dword ptr[ebx]
| 8b | 1c | a3 | | | mov ebx,dword ptr[ebx]
| 8b | 1c | e3 | | | mov ebx,dword ptr[ebx]
immediate
+----------+--------+--------+-----+--------------+-----------+
| prefixes | opcode | modR/M | sib | displacement | immediate |
+----------+--------+--------+-----+--------------+-----------+
The immediate value of an instruction is very simple, so a few examples should suffice:
prefixes | opcode | modRM | sib | disp | imm | disasm
--------------+--------+-------+-----+----------+----------+--------
| 04 | | | | aa | add al,aa
66 | 05 | | | | aaaa | add ax,aaaa
| 05 | | | | aaaaaaaa | add eax,aaaaaaaa
multiple representations
Now it's time for the good stuff :^)
playing fair with modR/M
If you take another look at the 16 and 32-bit modR/M tables, you'll notice that when the mod part is 0x3 (binary 11), the operand is not dereferenced. This can be used to create another representation of an instruction:
prefixes | opcode | modRM | sib | disp | imm | disasm
--------------+--------+-------+-----+----------+----------+--------
| 5a | | | | | pop edx
| 8f | c2 | | | | pop edx
playing fair with sib
In the sib table, you'll notice that whenever the index part is 0x4 (100 binary), that a scaled index isn't used. This can also let us make multiple representations of an instruction:
prefixes | opcode | modRM | sib | disp | imm | disasm
--------------+--------+-------+-----+----------+----------+--------
| 8b | 00 | | | | mov eax,dword ptr[eax]
| 8b | 04 | 20 | | | mov eax,dword ptr[eax]
| 8b | 04 | 60 | | | mov eax,dword ptr[eax]
| 8b | 04 | a0 | | | mov eax,dword ptr[eax]
| 8b | 04 | e0 | | | mov eax,dword ptr[eax]
being a bully
Now is where we start going into undefined territory.
Certain prefixes are only supposed to be used with certain instructions, and certain prefixes only make sense to be used when certain types of operands are used. For example, if a modR/M byte isn't used, the 0x67 prefix doesn't always do something:
prefixes | opcode | modRM | sib | disp | imm | disasm
--------------+--------+-------+-----+----------+----------+--------
67 | 58 | | | | | pop eax
However, sometimes the 0x67 prefix _does_ do something without a modR/M byte (thanks to MazeGen in the comments):
prefixes | opcode | modRM | sib | disp | imm | disasm
--------------+--------+-------+-----+----------+----------+--------
| a1 | | | 10203040 | | mov eax,dword ptr ds:[40302010]
67 | a1 | | | 1020 | | mov eax,dword ptr ds:[00002010]
The 0x2e and 0x3e (branch taken/not taken) prefixes are also intended only to be used with Jcc instructions. If they are used with another type of instruction, what happens? You guessed it, nothing:
prefixes | opcode | modRM | sib | disp | imm | disasm
--------------+--------+-------+-----+----------+----------+--------
2e | 58 | | | | | pop eax
3e | 58 | | | | | pop eax
There is a caveat to using 0x2e and 0x3e as "nop" prefixes. If the instruction dereferences something, then the 0x2e or 0x3e prefix will then be used as a CS or DS segment override:
prefixes | opcode | modRM | sib | disp | imm | disasm
--------------+--------+-------+-----+----------+----------+--------
| 8b | 00 | | | | mov eax,dword ptr[eax]
2e | 8b | 00 | | | | mov eax,dword ptr cs:[eax]
3e | 8b | 00 | | | | mov eax,dword ptr ds:[eax]
One other prefix that can potentially be useful is the lock prefix (0xf0). The lock prefix can only be used with the add, adc, and, btc, btr, bts, cmpxchg, cmpxch8b, dec, inc, neg, not, or, sbb, sub, xor, xadd, and xchg opcodes, and then
only if the dest operand is modifying memory. What does it do though? According to Intel, the lock prefix "forces an operation that ensures exclusive use of shared memory in a multiprocessor environment". Besides the restrictions on which instructions and types of operands it can be used with, the lock prefix can also be used to create another representation of an instruction.
being a bully*4
Earlier in this post I mentioned that up to four prefixes are allowed on an instruction, and that they can be in any order. This also applies to the "nop" prefixes: they can be in any order, but they can also be repeated:
prefixes | opcode | modRM | sib | disp | imm | disasm
--------------+--------+-------+-----+----------+----------+--------
67 | 58 | | | | | pop eax
6767 | 58 | | | | | pop eax
676767 | 58 | | | | | pop eax
67676767 | 58 | | | | | pop eax
67 | 58 | | | | | pop eax
6766 | 58 | | | | | pop ax
673e67 | 58 | | | | | pop eax
3e66672e | 58 | | | | | pop ax
If you take a look at this in windbg, you'll notice that it doesn't know how to disassemble the instruction. I'm assuming this is because windbg thinks that only one unique prefix is allowed per instruction:
0100c38c 67 ???
0100c38d 67 ???
0100c38e 67 ???
0100c38f 6758 pop eax
Even though windbg doesn't know how to disassemble it (haven't tested olly or ida yet or other debuggers), the instruction still executes just fine. This also goes for the lock+rep prefix combination example that I used earlier.
being a bully*14
Being a bully times 14? No way, you say. YES WAY. I decided to test the "rule" about having only four prefixes. It's a lie! In my testing, I was able to add up to fourteen prefixes before I started getting errors. Below are some examples:
prefixes | opcode | modRM | sib | disp | imm | disasm
--------------+--------+-------+-----+----------+----------+--------
6767676767676767676767676767 | 58 | | | | | pop eax
673e2e673e2e673e2e673e2e6767 | 58 | | | | | pop eax
windbg disassembly:
0100c3a2 67 ???
0100c3a3 67 ???
0100c3a4 67 ???
0100c3a5 67 ???
0100c3a6 67 ???
0100c3a7 67 ???
0100c3a8 67 ???
0100c3a9 67 ???
0100c3aa 67 ???
0100c3ab 67 ???
0100c3ac 67 ???
0100c3ad 67 ???
0100c3ae 67 ???
0100c3af 6758 pop eax
I did some additional testing on these extra prefixes, thinking that maybe anything before the last four prefixes don't get applied and can be any prefix, regardless of the compatability. It turns out this is not the case. All of the same rules still apply to all 14 prefixes.
Crazy stuff, huh? The biggest thing I learned from this is to question everything. I'm not used to having to question my disassembler too much. That's something I've been able to trust up to this point, at least for disassembling
_one_instrustion_. I almost missed seeing most of this behavior because the first few times I saw windbg fail to disassemble a single instruction, I thought it meant that it wouldn't execute. Luckily, I stepped (a literal hit-F10-and-execute-the-next-instruction step) through it anyways and noticed this behavior.
One other thing to note is that this isn't the first time somebody has run across the multiple-prefixes behavior. A quick conversation with Mark Dowd made it apparent that this behavior is pretty well-known, that different processors may allow even more than 14 prefixes, and that there are major differences in how emulators and native clients execute instructions.
I have other ideas for some more potentially interesting research in this area, but this is all for now. Laters.
 PFP takes an input stream and an 010 editor template and returns a modifiable DOM of the parsed data:
PFP takes an input stream and an 010 editor template and returns a modifiable DOM of the parsed data: